






AI Interview Series #4: Explain KV Caching
[ad_1] Question: You’re deploying an LLM in production. Generating the first few tokens is fast, but as the sequence grows,...
[ad_1] Question: You’re deploying an LLM in production. Generating the first few tokens is fast, but as the sequence grows,...
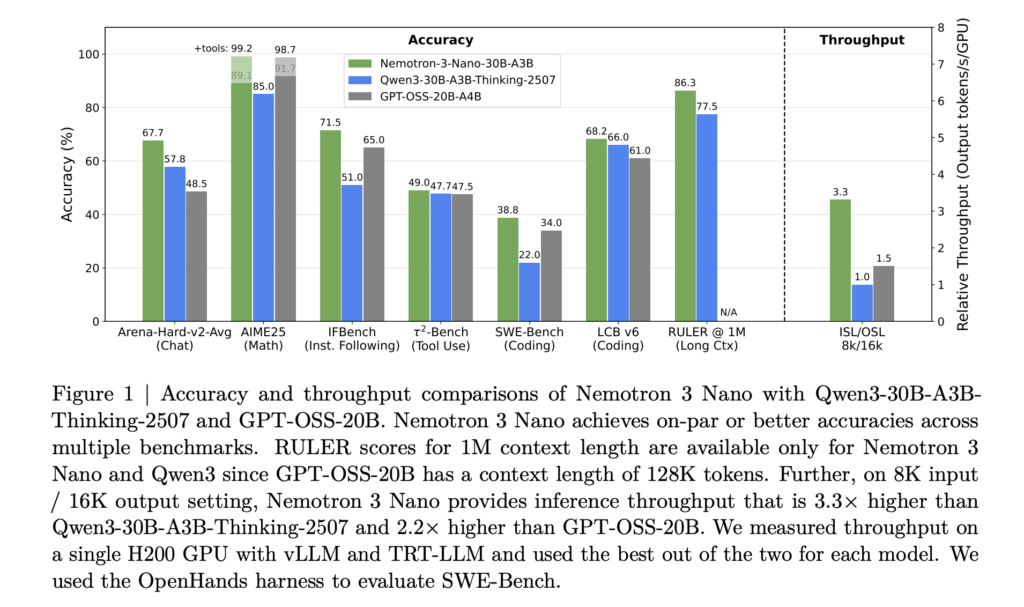
[ad_1] NVIDIA has released the Nemotron 3 family of open models as part of a full stack for agentic AI,...
[ad_1] In this tutorial, we devise how to orchestrate a fully functional, tool-using medical prior-authorization agent powered by Gemini. We...
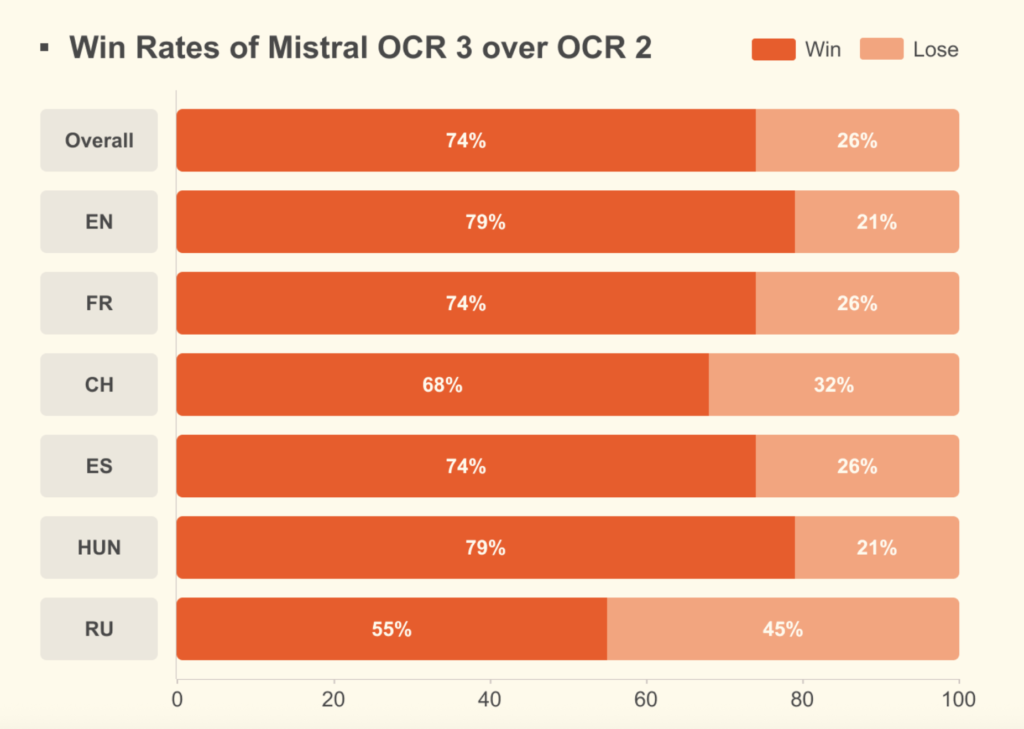
[ad_1] Mistral AI has released Mistral OCR 3, its latest optical character recognition service that powers the company’s Document AI...
[ad_1] In this tutorial, we build a fully functional event-driven workflow using Kombu, treating messaging as a core architectural capability....
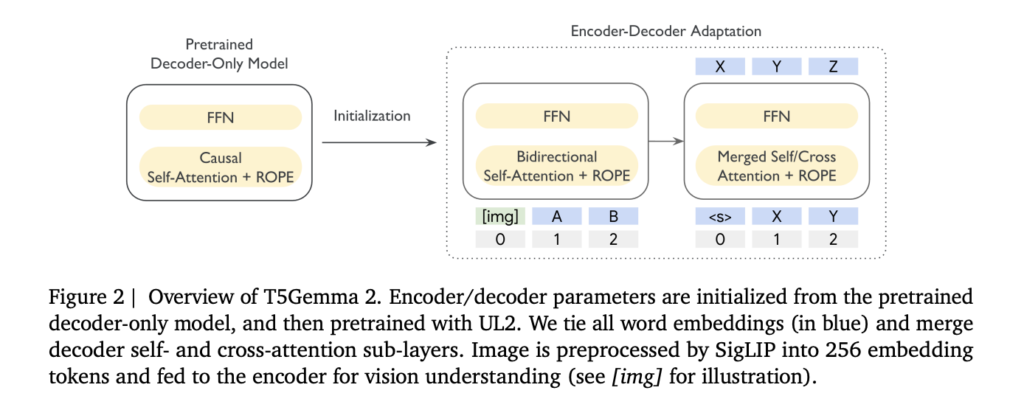
[ad_1] Google has released T5Gemma 2, a family of open encoder-decoder Transformer checkpoints built by adapting Gemma 3 pretrained weights...
[ad_1] In this tutorial, we shift from traditional prompt crafting to a more systematic, programmable approach by treating prompts as...
[ad_1] Fine-tune popular AI models faster with Unsloth on NVIDIA RTX AI PCs such as GeForce RTX desktops and laptops...
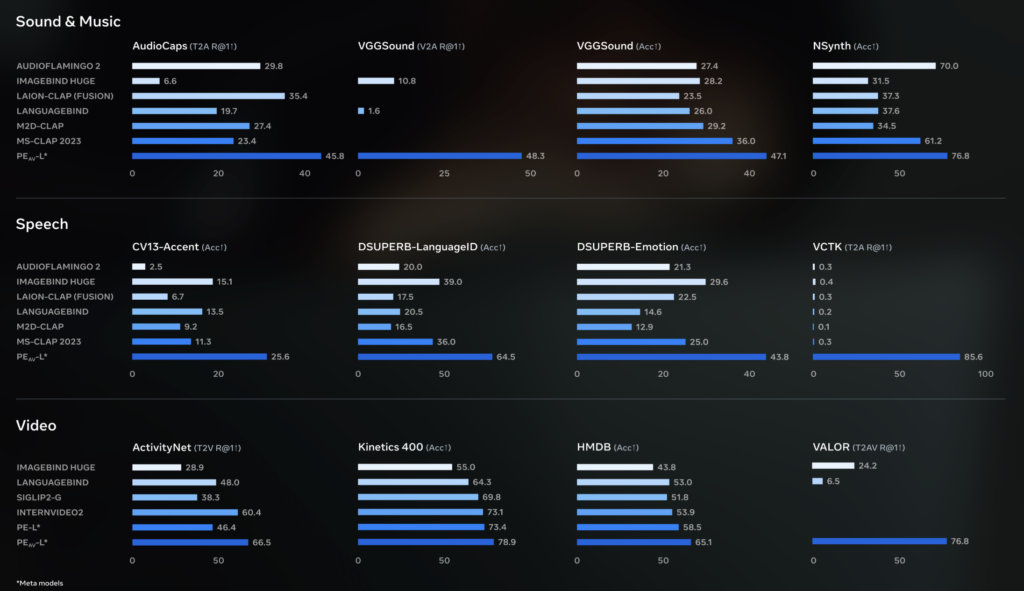
[ad_1] Meta has released SAM Audio, a prompt driven audio separation model that targets a common editing bottleneck, isolating one...
[ad_1] In this tutorial, we implement how we build a small but powerful two-agent CrewAI system that collaborates using the...