

AI Interview Series #4: Transformers vs Mixture of Experts (MoE)
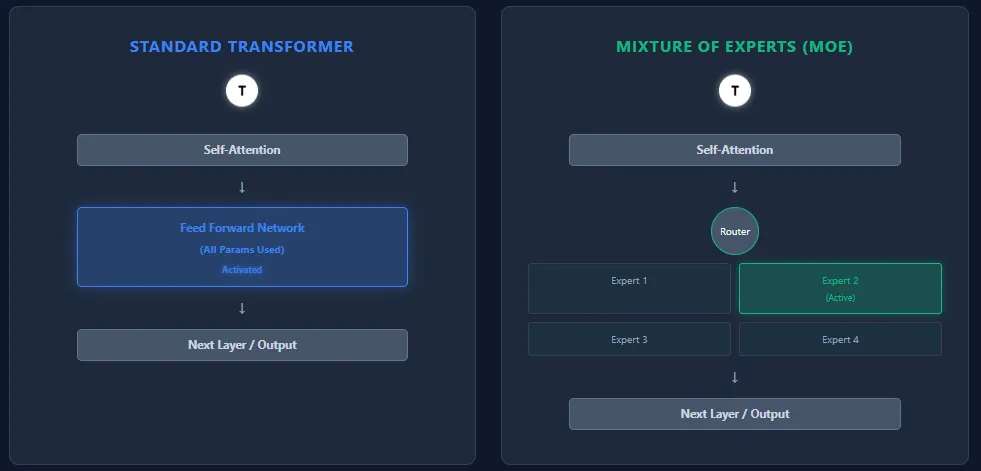
[ad_1] Question: MoE models contain far more parameters than Transformers, yet they can run faster...
[ad_1] Question: MoE models contain far more parameters than Transformers, yet they can run faster...
[ad_1] NVIDIA announced today a significant expansion of its strategic collaboration with Mistral AI. This partnership coincides with the release...
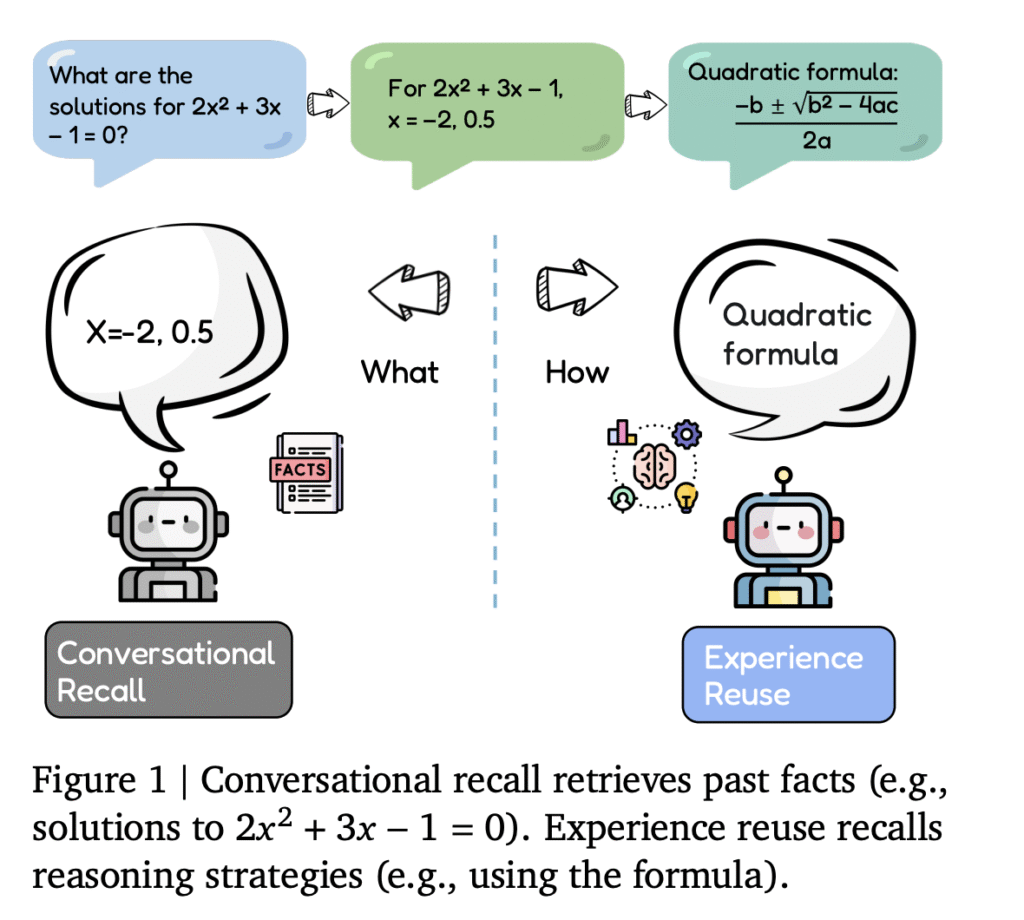
[ad_1] Large language model agents are starting to store everything they see, but can they actually improve their policies at...
[ad_1] In this tutorial, we explore Online Process Reward Learning (OPRL) and demonstrate how we can learn dense, step-level reward...
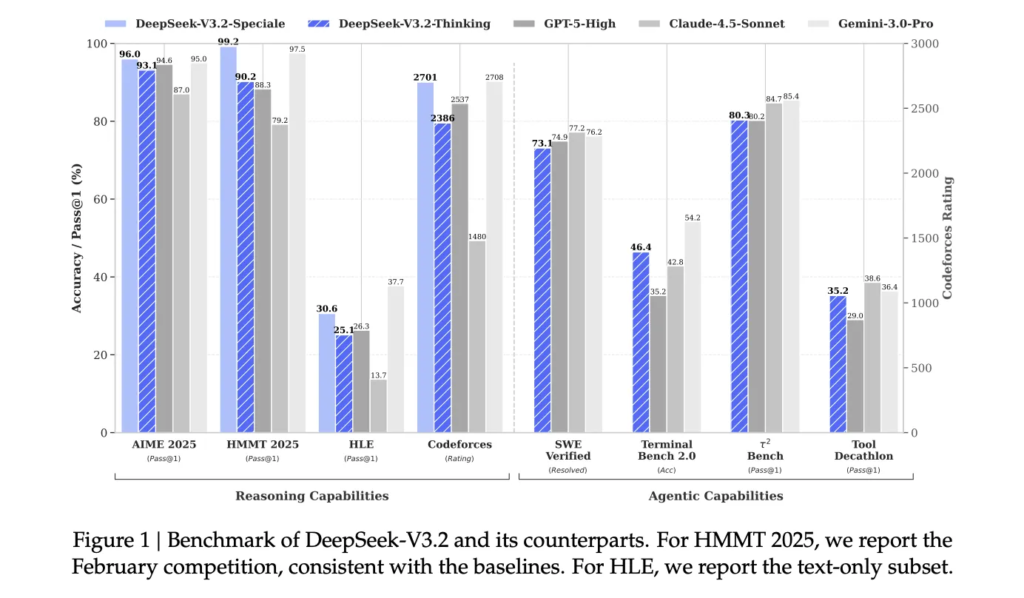
[ad_1] How do you get GPT-5-level reasoning on real long-context, tool-using workloads without paying the quadratic attention and GPU cost...
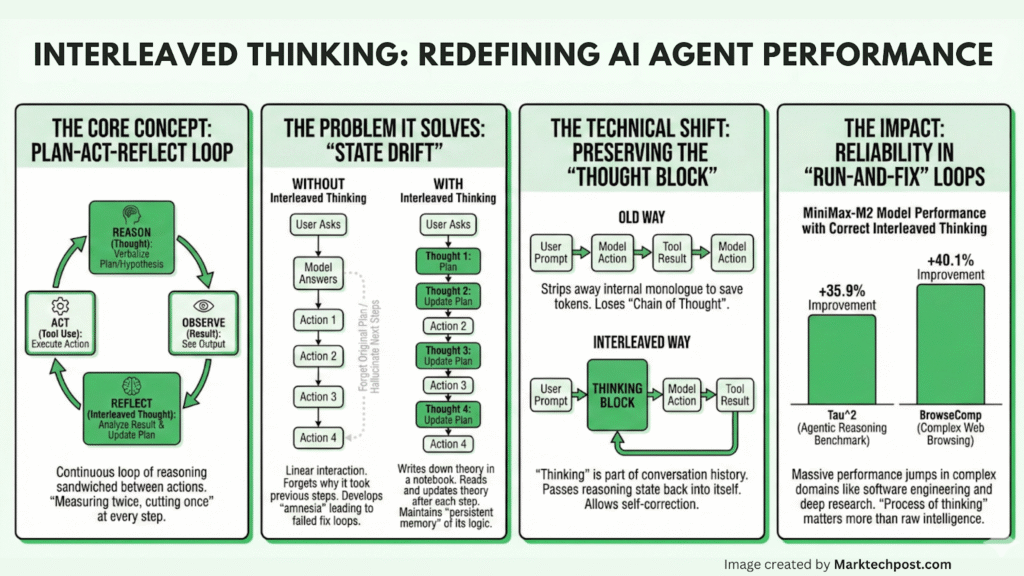
[ad_1] The AI coding landscape just got a massive shake-up. If you’ve been relying on Claude 3.5 Sonnet or GPT-4o...
[ad_1] In this tutorial, we build an advanced multi-page interactive dashboard using Panel. Through each component of implementation, we explore...
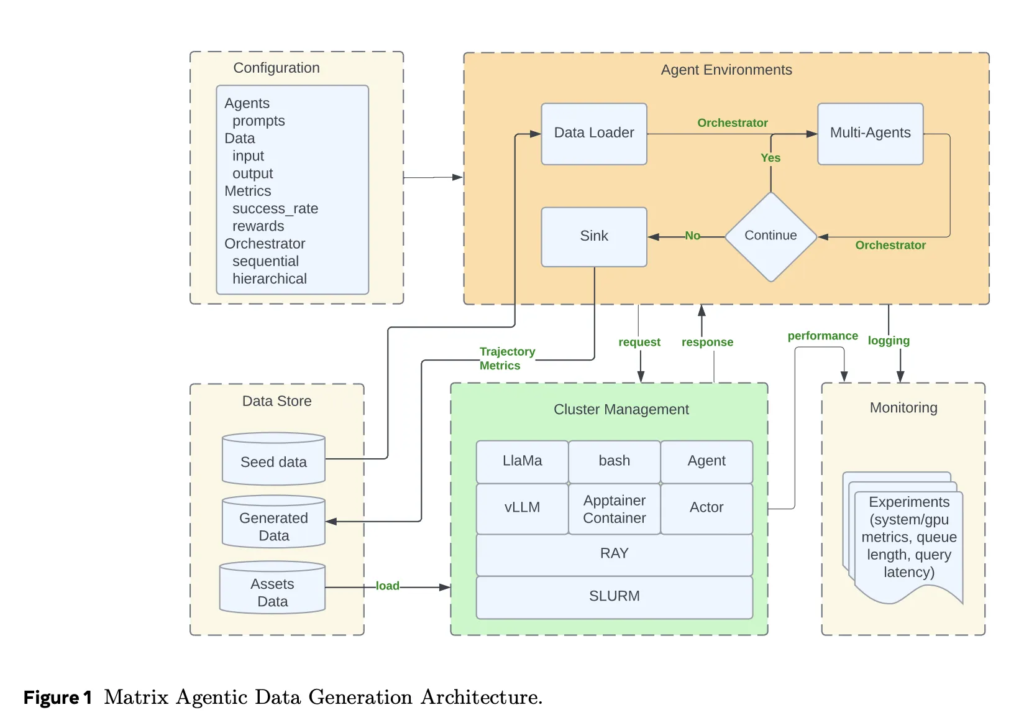
[ad_1] How do you keep synthetic data fresh and diverse for modern AI models without turning a single orchestration pipeline...
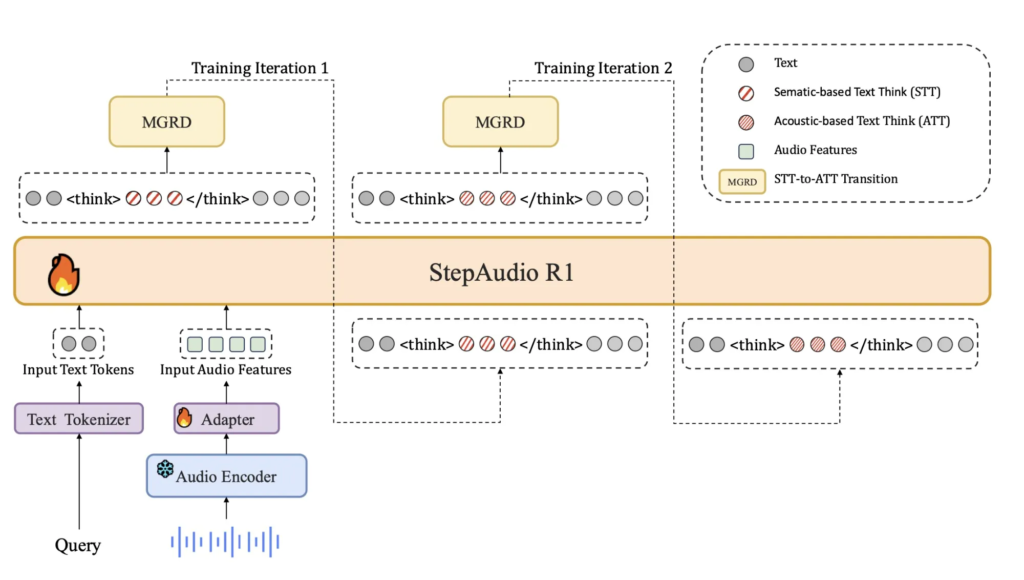
[ad_1] Why do current audio AI models often perform worse when they generate longer reasoning instead of grounding their decisions...
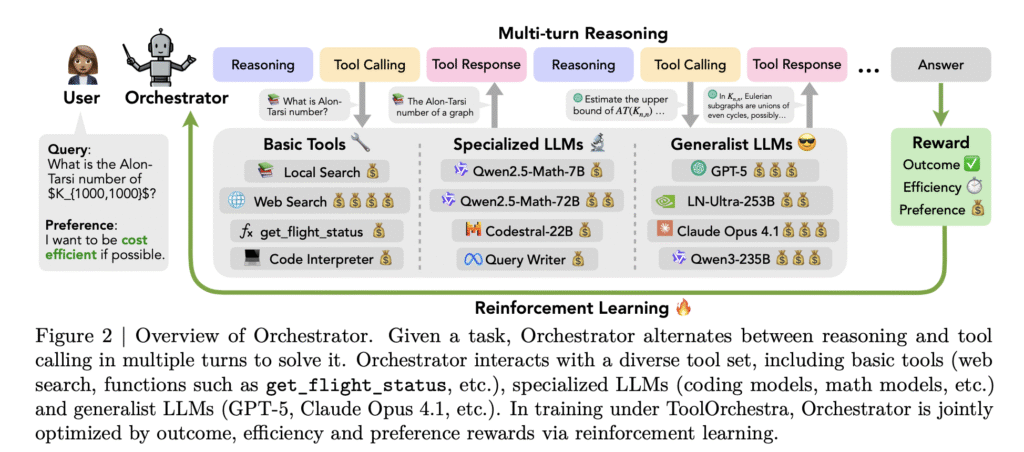
[ad_1] How can an AI system learn to pick the right model or tool for each step of a task...